Machine Learning in Compiler Optimization

Why ML to build Compilers ?
My primary aim of interest is in using Machine Learning to improve the decision making of compilers. Compilers do translate programming languages into binary used by hardware. ML, on the alternative hand, may be a locality of AI (AI) geared toward more investigation and predicting patterns. Possibly it appears these domains are different and are too vast but we shall see further how compilers and machine learning are a natural fit and have grown into an established research domain.
Compiler have 2 jobs — translation and optimization. They must 1st translate programs into binary properly. second they need to search out the foremost economical translation potential. There square measure many various correct translations whose performance varies considerably. The overwhelming majority of analysis and engineering practices is focussed on this second goal of performance. Machine learning brings compilation nearer to the standards of proof based mostly science. It introduces an experimental methodology wherever we have a tendency to filter out analysis from style and considers the lustiness of solutions. Machine learning based mostly schemes generally have the matter of hoping on black-boxes whose operating we have a tendency to don’t perceive and thus trust.
Process of ML on Compilers
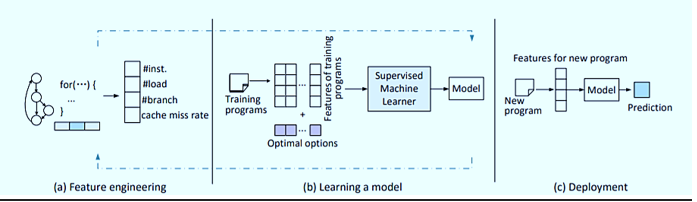
The above figure gives a brief view, how ML can be applied to compilers. This process which includes feature engineering, learning a model and deployment is described below.
- Feature Extraction Engineering
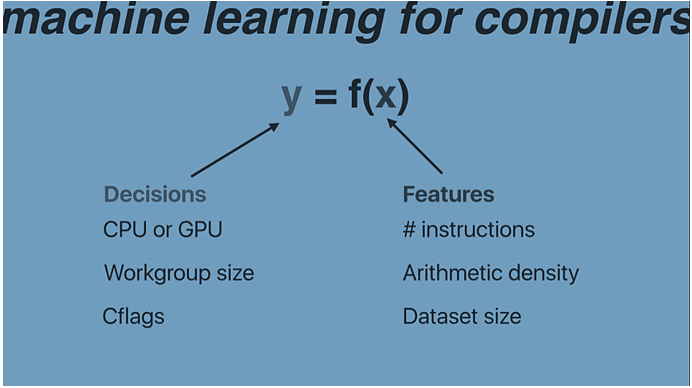
First of all we first need to be able to characterize program features. Machine learning always relies on a quantifiable properties, or features, to characteristics of the programs. These features include the static data of structures extracted from the program code or the compiler intermediate representation , dynamic profiling information obtained through runtime profiling, or a combination of the both. Standard ML algorithms typically work on fixed length of inputs, so the selected properties will be summarized into a fixed length feature vector sets. Elements of the vector can be integer, real or Boolean value. The process of feature selection and tuning is referred as Feature Extraction or Engineering. This process may need to perform multiple times to find a set of high-quality features to build a accurate ML model.

2. Learning Model
We have to use training data to derive a model using a ML algorithm. The compiler developer will select programs which are typical of the application domains. For each training program, we calculate the feature values Vector, then compiling the program with different optimization techniques and timing the compiled binaries to discover the best-performing options. For each training program, a training instance that consists of the feature values and the optimal compiler option for the program is created. The compiler developer then feeds these examples to a suitable ML algorithm to automatically build a model. The learned model can be used to predict, for a new set of feature vectors, what the optimal optimization options should be. Because the performance of the learn model strongly depends on how well the features and training program is chosen.
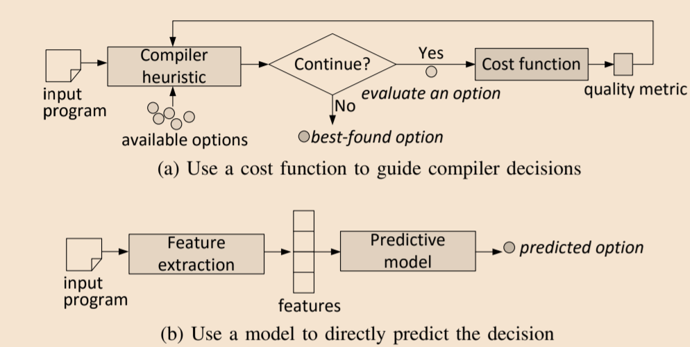
There are in two models to determine the optimal compiler decision using machine learning. The first one is the compiler heuristic based. This model is to learn a cost or priority function to be used as a proxy to select the best-performing option heuristically. The second one is to learn a predictive model to predict directly the best option.
3. Deployment
This is final step where, the learned model is to be inserted into the compiler to predict for the best optimization decisions for new programs. To make a prediction, the compiler first extracts the features from the input program, and then feeds the extracted features values to the learned model to make a predictions.
The advantage of the ML based approach is that the entire process of building the model can be easily repeated whenever the compiler needs to target a new hardware architecture, operating system, or application domain. The model built is entirely derived from experimental results, feature vectors and is hence evidence based.
Machine Learning Models
There are wide number of ML models on the compiler optimization. For code transformation we use naive approach, it is to exhaustively apply legal transformation option and then program to collect the relevant performance metrics. Given that many compiler optimization problems have a massive number of options, exhaustive search and profiling is infeasible, which prohibits the use of this approach at scale.

Mainly there are two main sub-divisions of the ML models i.e. supervised and unsupervised learning for compiler optimization. Using supervised machine learning model, a predictive model is trained on performance data and important quantifiable properties like features vectors of programs. The learned correlations between features and optimization decisions are used to predict the best optimization decisions for newer programs. Depending on the output, if the nature is continuous predictive model can be a regression model or if the nature is discrete the classification model is selected.
For the unsupervised learning, the input for the learning algorithm is a set of input values. In unsupervised learning there is no labelled output. One form of unsupervised learning is clustering, which groups the input data items into several subsets. It does so by first dividing a set of program runtime information into groups (or clusters), such that points within each cluster are similar to each other in terms of program structures like loops, memory usages etc. Then it chooses a few points of each cluster to represent all the simulation points within that group without losing much data.
Conclusion
The way compilers are evolving it need to optimize for better performance. As Machine learning is quickly growing field in computer science. It has applications in nearly every other field of study and is already being implemented commercially because machine learning can solve more difficult problems in optimize way. We can use Machine learning for compiler optimization. Here compilation is now a mainstream compiler research area and over the last decade or so, has generated a large amount of academic interest and research papers. While it is impossible to provide a definitive cataloguer of all researches, we have tried to provide a brief comprehensive and accessible survey of the main research areas and future directions.
Hope you enjoyed reading. Feel free to drop in your opinions and suggestions in the comments section.